




ANDMEHALDUS JA ANDMEBAASID
Andmed ja informatsioon
Informatsioon e. teave - fakte, sündmusi, asju, protsesse, ideid, mõisteid või muid objekte puudutav teadmus, millel on teatud kontekstis eritähendus.
Organisatsioonis vajaminevat informatsiooni säilitatakse põhiliselt dokumentides (digitaalsel või paberlikul kujul), andmeid aga enamasti andmebaasides.
Infot võib defineerida kui sõnumit, mis esineb dokumendi või audiovisuaalses vormis oleva kommunikatsioonina. Nagu igal sõnumil, on ka infol saatja ja vastuvõtja. Info ülesanne on mõjutada vastuvõtja hinnanguid või käitumist. Erinevalt andmetest on infol tähendus, olulisus ning eesmärk. Andmed muutuvad infoks, kui nende looja lisab neile tähenduse. Oluline on märkida, et IT aitab andmeid infoks muuta ja neile väärtust lisada. Samas ei aita IT kaasa konteksti loomisele (kategooriad, kalkulatsioonid, vorm) - selle loovad inimesed.
Andmeteks (data) nimetatakse inimesele ja/või masinale arusaadaval kujul formaliseeritud (erilisel viisil vormindatud) info esitusviisi, mida saab kasutada suhtluseks, tõlgendamiseks, säilitamiseks või töötluseks.
Andmed on üksikasjalikud, objektiivsed faktid sündmustest. Kõik organisatsioonid vajavad andmeid ning neil baseerub enamik eluvaldkondi. Efektiivne andmehaldus on üks olulisemaid edukuse kriteeriume, seevastu suur andmete hulk seda tingimata veel ei ole.
Suurest andmehulgast pole võimalik objektiivelt täpseid otsuseid automaatselt järeldada kahel põhjusel. Esiteks, andmete liiga suur kogus teeb raskeks nende identifitseerimise ja nende tähtsuses selgusele jõudmise. Teiseks (see on ka peamine põhjus), andmeil loomupäraselt tähendust ei ole. Andmed iseloomustavad või kirjeldavad vaid toimunut, nad ei sisalda hinnangut ega inspiratsiooni. Organisatsiooni jaoks on andmed siiski olulised, kuna nende põhjal luuakse infot. Andmeelemendiks nimetatakse antud kontekstis (sisuga seotud) jagamatut andmeüksust.
Iga tarkvaraline rakendus haldab ja manipuleerib andmeid, milliseid võib tõlgendada kui töötlusseadme sisemisi muutujaid või nagu algupäraseid ja kohaseid teatud objekte ("data" ladina keeles, ja "données" prantsuse keeles), need on informatsioonielemendid, milliseid vahetatakse kasutajatega või väliste süsteemidega.
Andmetüpoloogia ülesanne on rühmitatud vastavalt nende päritolu allikale/kanalile (Sisend) ja sihtpunktile (Väljund) ja me võime ideaaljuhul katalogiseerida tarkvara süsteeme viies rakenduste kategoorias:
- ("sisemiste" andmete) algoritmiline töötlus
- automatiseerimine ja juhtimine (sisend/väljund (I/O) muunduritelt/anduritelt ja muunduritele/anduritele)
- inim-masin liides (I/O kasutajalt ja kasutajale)
- andmeedastus / ülekanne (I/O töötlusvõrgust ja töötlusvõrku)
- ülekandesüsteemid ja andmepangad (I/O pidevsalvestussüsteemist ja pidevsalvestussüsteemile).
Andmebaas
Andmebaas (database) on omavahel seotud ja süstematiseeritud andmete kogum.
Kõige elementaarsemas tähenduses mõistetakse andmebaasi all andmekogumit, mis lisaks andmetele sisaldab eneses ka nende andmete struktuuri kirjelduse - andmetega koos hoitakse ka nende andmete kirjeldust. Võib öelda ka veel nii: andmebaas on kogum andmeid koos neid andmeid (andmete struktuuri) kirjeldavate meta-andmetega. Kõige elementaarsemal tasemel sisaldab andmete kirjeldus tabelite kirjeldusi (milledes hoitakse andmeid) ja tabelite vaheliste seoste kirjeldusi.
Tänapäeva andmebaasisüsteemid hoiavad andmebaasides lisaks andmete kirjeldustele ka andmeid käsitlevaid protseduure ja nende protseduuride käivitamise reeglid (trigerid (triggers) ja kalenderplaanid (schedulers).
Laiemas mõttes ei tohi andmebaaside all mõista ainult elektroonilisi andmebaase, mis on realiseeritud arvutisüsteemides. Andmebaasid eksisteerisid palju aega enne seda, kui neid sai hakata realiseerima arvutisüsteemides. Suvalised kartoteegid on andmebaasid - olenemata sellest, milline on andmekandja selle kartoteegis (kartoteegikaart, kivitahvel, perfolint, perfokaart vms.).
Sama andmebaasi piires peavad andmebaasis olevad andmete kirjeldus ja andmed olema alati tõlgendatavad ühte moodi - nad peavad olema salvestatud kindlaks määratud ülesehitusega füüsilise struktuurina.
Elektroonilises mõttes on andmebaas arvutiprogramm, mis võimaldab andmeid hoida ja kasutaja(te)le neid kuvada soovitud vormingus. Andmebaasides hoitakse informatsiooni teatud objektide kohta. Levinuim, relatsiooniline andmebaas koosneb mitmetest andmetabelitest. Ühes tabelis hoitakse tavaliselt ühe kindla kategooria objekti (tööpink, auto, isik, töötaja) kohta kogutud andmeid. [5]
Andmebaaside näited:
- haiguslugude andmebaas haiglas
- raamatute kataloog raamatukogus
- abielude registreerimise ja lahutuste andmebaas perekonnaseisuametis jne.
Elektrooniliste andmebaasisüsteemide arengu algus
Elektrooniliste andmebaaside (esialgu küll kartoteekide) loomisele andsid peamise tõuke kolm asja (antud järjekorras) - kaasaaegse struktuuriga arvuti loomine, aine magnetilistel omadustel baseeruva püsimälu loomine ja andmete lugemise-kirjutamise otsepöördus (mitte-järjestik) süsteemide loomine. Siin ei saa muidugi tähtsa katalüsaatorina jätta mainimata seda, et selleks ajaks oli loodud hulk strateegilise tähtsusega kartoteeke, mille pidamine vanal tehnilisel ja struktuursel platvormil hakkas üle jõu käima.
Kaasaaegse arvuti esimese põlvkonna (1945-1956) tekkimisel oli suur osakaal teisel maailmasõjal, kus riigid püüdsid arvutite abil saavutada strateegilist üleolekut - sõja ajal tehtud pingutused kanaliseerusid vahetult pärast sõda uue põlvkonna arvutite loomisega, milles rakendatud põhimõtted määrasid arvutite arendamise trendid järgmiseks neljakümneks aastaks (EDVAC - University of Pennsylvania 1945, EDSAC - Cambridge University 1949, UNIVAC I - Remington Rand,1951). Peamisi põhimõttelisi muutusi oli kaks. Esiteks kirjeldati arvuti arhitektuuris keskjuhtseadme (protsessori) mõiste, mis võimaldas arvutit juhtida läbi ühe andmevoo. Teiseks hakati nii täidetavat programmi kui ka programmi juhtimiseks või töötlemiseks vajalikke andmeid hoidma samas mälus. See kõik lõi aluse kaubanduslikuks arvutite tootmiseks.
1945. aastal loodi uus andmekandja, magnetlint, mis vähehaaval hakkas välja vahetama perfokaarte ja perfolinte. See oli esimene andmekandja, mis võimaldas andmete otsimist. Siiski ei olnud see otsingumehhanism veel eriti täiuslik, kuna võimalik oli ainult järjestik-otsing. Suure tähtsusega oli aga see, et "ruumiühikusse salvestatud andmete hulk" kasvas mõõtmatult ja andmete fragmenteerimisega paljudele paralleelselt töös olevatele lintidele suudeti tagada ka juba piisav operatiivsus andmete otsimisel.
Esimeste kaasaaegsete andmebaasisüsteemide loomiseni oli aega veel umbes paar aastat, kui William. C. McGee 1959. aastal publitseeris oma artikli "Generalization: Key to Successful Electronic Data Processing" ajakirjas Journal of the ACM (Volume 6, Number 1, January 1959 lk. 1-23, ACM - Association for Computing Machinery). Artiklis ei anta küll veel konkreetseid andmete üldistamise põhimõtteid vaid piirdutakse üldkontseptuaalse filosoofiaga, kuid see on esimene suunda näitav teeviit kaasaaegse andmete modelleerimise põhimõtete poole.
Samal aastal võtab IBM kasutusele oma magnetkettasüsteemi Ramac (Random Access Method of Accounting and Control) mudel 305, mis on maailma esimene magnetkettasüsteem ja mis koosneb 50-st umbes 60 cm diameetriga kettast, millede mõlemale küljele saab salvestada informatsiooni. Informatsiooni salvestamise tiheduseks on 2000 bitti ruuttollil kogumahuga 5MB. Olulisimaks murranguks on siin siiski andmete otsepöördus lugemis/kirjutusrežiimi esmakordne rakendamine ja andmete kirjutamise/lugemise suur kiirus.
Aastal 1961 töötati korporatsioonis General Electric Co. välja andmebaasi juhtimissüsteem IDS, mida loetakse esimeseks elektrooniliseks andmebaasi juhtimise süsteemiks.Projekti juht oli Charles Bachman. Siin ei saa muidugi rääkida veel andmebaasi juhtimissüsteemist tänapäevases tähenduses, kuna enamik andmebaasi funktsioone oli käsitsi kodeeritud, andmebaasina oli käsitletav ainult üks fail ja ta töötas ainult General Electric Co. arvutitel ja lahendas ainult selle firma konkreetseid vajadusi. Sellest sai tõuke CODASYL (Conference on Data Systems Languages) grupi kokkukutsumine, mis koosnes vabatahtlikest ja mille eesmärgiks oli andmesüsteemide efektiivsema analüüsi, disaini ja rakendamise vahendite ja metoodikate väljatöötamine. Grupp moodustati 1959 aastal ja töötas kuni 1985-nda aastani. Grupi peamiseks ülesandeks määratleti standardse, erinevatel arvutitel kasutatava programmeerimiskeele loomine. Selleks programmeerimiskeeleks sai COBOL ja selle raames formuleeriti ka võrk-andmemudeli põhilised kontseptsioonid.
1968.aastal tuli IBM välja oma IMS (Information Management System) kontseptsiooniga mis formuleeris hierarhiliste andmemudelite põhialused. Ja seejärel kohe (1969) sama mudeli täiendusega (IDM DB/DC), mis kirjeldas meetodit võrk-vaadete ehitamiseks hierarhilisele andmemudelile. Mõlemad lahendused olid mõeldud kasutamiseks IBM SYSTEM/360 mainframe'del.
Kuni siiani olid andmebaasid kõik ühe protsessi poolt kasutatavad. Eelmise sajandi 70-ndate aastate lõpus lõi IBM koos American Airlines'ga süsteemi SABRE, kus läbi kommunikatsioonivõrgu said andmetele korraga ligi juba paljud kasutajad.
Vaatamata suhteliselt tormilisele erinevate andmebaaside loomisele eelmise sajandi 70-ndate aastate lõpus, ei olnud ikka veel tekkinud kommertsiaalsetel alustel müüdavat, ristvarast eraldiseisvat andmebaasisüsteemi. Sellele aluse panemiseks oli jällegi suur teene firmal IBM. IBM uurija Edgar F. Codd pakkus 1970.aastal välja relatsioonilise andmebaasimudeli, kus andmeid säilitatakse tabelites mille vahele ehitatakse relatsioonid. IMS mudelit täiendati relatsioonilise andmemudeli printsiipidega ja selle alusel arendati välja andmebaasisüsteem SYSTEM/R, mida müüdi koos IBM mainframe'dega kuni 1980.aastani. IBM süsteemi SYSTEM/R kohta avaldatud informatsiooni võtsid oma uurimis- ja arendustöödes aluseks California Ülikooli teadlased Michael Stonebraker ja Eugene Wong ning lõid nende arenduste tulemusena oma andmebaasisüsteemi, millele andsid nimeks Ingres ja millel olid kõik kommertsialiseerimiseks vajalikud olulised omadused. See produkt kommertsialiseeriti lõpuks firmade Oracle Corp. ja Ingres Corp. poolt.
Aastast 1979 tasub ära märkida veel sündmus, mis märkis ühe tõusva produkti ja trendi sündi. 70.ndate aastate jooksul töötati välja mitmeid erinevaid päringukeeli -SQUARE, SEQUEL, QBE, QEL jne. 1979. aastal tõi Oracle turule esimese kommertsiaalse andmebaasisüsteemi, mis kasutas andmemanipuleerimiskeelena SQL-keelt (Oracle Corp. teisend standardist SEQUEL). Tõusvaks tooteks sai Oracle DBMS ja tõusvaks trendiks SQL-keel.
60-ndate aastate lõpust hakkas arenema veel üks süsteemide grupp, mis tänapäeval on suurte andmebaaside kasutamise lahutamise koostisosa. Esialgu nimetati neid otsuse toetussüsteemideks (DSS - Decision Supporting System).ja nende esmane eesmärk oli andmekäsitluse lihtsustamine ja parem kasutamine otsuste tegemise toetamisel. Sisuliselt olid tegemist andmete käsitlemise analüütiliste vahendite arendustega. Selliseid alamsüsteeme loodi küll kogu eelmise sajandi 70-ndate aastate jooksul kuid esimese kommertsiaalse lahenduseni jõuti alles 1970.aastal. Selleks oli süsteem EXPRESS. [5]
Andebaasid ja personaalarvutid
Eelmise sajandi 80-ndate aastate alguseks oli põhiline platvorm andmete modelleerimise ja andmebaasisüsteemide arenemiseks loodud ja tundus, et mingisuguseid erilisi lööke ei edasi ega tagasi ei tohiks tulla. Selle situatsiooni lõi aga segamine personaalarvutite turuletulek.Üpris pea loodi esimene personaalarvutile mõeldud relatsiooniline andmebaasisüsteem DBase.Kiiresti järgnesid DBase II, Paradox, Fox, FoxPro, DBase III, Dbase IV jne. See muutis olukorda pöördeliselt -andmebaasid said kättesaadavaks suurele kasutajate hulgale ja andmete modelleerimise metoodikad ja vahendid vajalikuks paljudele. Arendama asuti järjest uusi ja mugavamaid kasutajaliideseid.
Mõne aja pärast lisandusid lokaalvõrkude loomise vahendid - riistvara ja tarkvara. Oma hüppe tegid kaasa ka andmebaasisüsteemid - kõigile elujõulistele andmebaasisüsteemidele lisati andmete mitme kasutaja poolt samaaegse kasutamise omadused. See ei osutunudki aga nii lihtsaks kui esialgu tundus - hakkasid tekkima konfliktsituatsioonid andmete samaaegsete kasutajate vahel ja see tingis andmete ühiskasutuse ja lukustusteooriate arenemise.
1985.aastal publitseeriti SQL-keele esialgne standard - keel, mille Oracle Corp. oli kasutusele võtnud kui oma andmebaasisüsteemi andmemanipuleerimiskeele, oli vahepeal läbi teinud standardiseerimise protsessi ja valmis kasutamiseks suuremas hulgas produktides. Praeguseks on toona kinnitatud standardit mitmeid kordi muudetud ja ANSI klassifikatsiooni järgi on viimane standard SQL99, mida arvestavad oma uutes versioonides kõik tuntumad andmebaasisüsteemid.
1985.aasta oli nii mõneski mõttes huvitav aasta. Lisaks SQL-keele esmase standardi esitlemisele rakendati samal aastal ka esimene äri-intelligentsi (business intelligence) süsteem. Firma Metaphor Computer Systems Inc. valmistas Procter& Gamble Co. jaoks süsteemi, mis ühendas analüüsiks müügiinformatsiooni ja turu jälgimise informatsiooni. Samal aastal alustas Pilot Software Inc. süsteemi Command Center müüki - turule oli tulnud esimene Client/Server arhitektuuriga süsteem. Seoses sellega hakkasid ka kohe arenema eraldatud (distributed) struktuuriga andmebaaside teooriad ja õigepea ka andmete replikeerimist käsitlevad teooriad ja toetavad süsteemid. Paraku ei ole lõpuni korrektselt toimivate ja kõiki kasutamisvajadusi rahuldavate replikeerimissüsteemide loomiseni jõutud veel tänasel päevalgi.
80-ndate aastate lõpus toimus suur murrang andmebaasisüseemide arhitektuuris. Siis tekkinud arhitektuur kestab väikeste muudatustega tänaseni. Selle arhitektuuri nimi on klient/teenindaja (client/server). Kui siiani pöördusid andmebaasijuhtimissüsteemid arvutivõrgus oleva andmebaasi poole kui võrguketta poole, siis nüüd muutus suhtlus andmebaasiga teadete põhiseks. Selles arhitektuuris on kaks osapoolt - klient e. rakendusprogramm ja andmebaasi serveri mootor (andmebaasi serveri täiturprogramm). Klient saadab serverile teate korraldusega ja server saadab omakorda oma poolse teate või teadete seeriaga vastused. Selleks vastuseks võib olla lihtsalt teade selle kohta, kas korralduse täitmine õnnestus või mitte (viimasel juhul tagastatakse teatega vea number ja kirjeldus) või siis korraldusega (päringuga) tellitud andmed.
Sellest hetkest alates on toimunud tehniliste vahendite stabiilne areng ilma suuremate hüpeteta. Täiustatud on tehnilisi võimalusi, kiiremaks on muutunud riistvara ja optimiseeritud ning täiustatud on andmekäsitlusalgoritme ja meetodeid. [5]
Andmebaasiprogrammid jagunevad:
- lameandmebaasideks (hierarhilisteks andmebaasideks), kus andmed reastatakse puustruktuurina, s.t. allolevad andmed on seotud ülemistega ja neile pääseb ligi ainult ülemiste andmete kaudu
- relatsioonandmebaasideks, kus andmeüksused on omavahel relatsioonidega (seostega) ühendatud. Neid relatsioone esitatakse põhimõtteliselt tabelitena, kusjuures veergudes kujutatakse andmevälju (näit. isikukood, nimi, eesnimi, haridus, perekonnaseis jne.) ja ridades andmeüksusi e. kirjeid (näit. töötaja isikuandmed).
Lisaks ülalmainitud laiatarbeprogrammide kasutatakse väga palju erialasteks rakendusteks (arstidele, arhitektidele, juristidele, raamatupidajatele jne.) mõeldud tarkvara, mida saab ilma lisasobitusteta kohe kasutada. Sellist tarkvara nimetatakse ka vertikaalseks tarkvaraks. Nende põhiline erinevus standardprogrammidest seisneb selles, et neid valmistatakse suhteliselt väikestes kogustes ja nende hind ületab mitmekordselt laiatarbeprogrammide hinna. Tihti on nad kirjutatud mõne relatsioonandmebaasiprogrammi programmeerimisvahendeid kasutades.
Kui on 2..3 sõpra, siis nende telefoninumbreid ja aadresse suudame meelde jätta. Kui on mõni tuhat sõpra ja tuttavat, siis nende nimede ja telefoninumbrite meelespidamiseks ei piisa ka mobiiltelefoni mälust. Mida sellisel korral ette võtta?
Võiks kirjutada kõik nad mingisugusesse arvuti poolt hallatavasse programmi. Milline aga see programm peaks olema, mis võimaldaks vajaliku isiku kiiresti leida ja näitaks kohe ka tema telefoninumbrit?
Siin tuleb appi andmebaasirakendus, mis võimaldab sellist hulka andmeid paigutada ja ka kiiresti otsingud, ükskõik millise kriteeriumi järgi, teostada.
Andmete salvestamine
Arvutiprogrammi, milline hoiab andmeid ja võtab vastu kasutajate päringuid ning väljastab päringu põhjal vajalikud andmed (kui leiduvad!) vajalikul kujul nimetatakse andmebaasi haldussüsteemiks (ABHS) (database management system (DBMS)).
Andmed salvestaks reeglina mingisuguses andmebaasis. Andmebaasi võib defineerida ka kui kirjete kogumit, mis paiknevad arvuti salvestusseadmel, nii, et kui kasutaja pöördub arvuti poole sooviga teatud informatsiooni saada mingi otsuse tegemiseks, siis arvuti konsulteerib andmebaasiga ja kui soovitud andmed leiduvad, siis väljastab need kasutajale. Andmete paremaks kättesaamiseks (leidmiseks) andmebaasist on kirjed reeglina organiseeritud andmeelementide (faktide) kogumina.
Andmebaaside kasutamine võimaldab:
- Kiiret juurdepääsu vajalikele andmetele
- Andmete sorteerimist etteantud tunnuste järgi
- Ainult vajalike andmete leidmist ilma liigse "infomürata"
- Mitme kasutaja üheaegset juurdepääsu andmetele
- Mitmest füüsiliselt eraldi asuvast asukohast andmesisestust
- Andmetele juurdepääsu ainult volitatud isikutele.
Andmebaaside kasutamine tõstatab ka rea probleeme:
- Andmeid on vaja kaitsta volitamata isikute eest
- Andmebaasihaldussüsteem (ABHS) ehk programm on vaja soetada
- ABHS kasutajaid ja haldajaid on vaja koolitada
- Andmete terviklikkus on vaja tagada
- Andmed on vaja sisestada etteantud kujul
- Andmebaasid vajavad projekteerimist ja see nõuab aega.
ABHS täieliku usaldusvääruse klassikaliseks näiteks on jooksevkonto kontrollimise operatsioon. On vaja tagada, et igal elujuhtumil (ka katastroofiolukorras) andmete usaldusväärus ei kannataks ja iga online tehingu (ülekande) korral ei peaks liidetama saaja kontole summat ilma seda saatja kontolt maha võtmata ning vastupidi.
Ülekannete vajalikku turvalisust iseloomustab lühend "ACID", mõnikord kasutatav ka kui "ACID test", mis tuleneb terminitest:
- atomaarsus (Atomicity) - ülekanne peab olema jagamatu, saabudes kehtivalt (juriidiliselt) lõpetatuna (soorita tehing=commit) ja vastasel korral tühistatuna (jäta tehing ära=rollback), viimane taastab andmete esialgse seisu (seis enne tehingu alustamist), mis loogikaterminites tähendab kõik või mitte midagi
- kooskõlalisus (Consistency) - sobivalt valitud andmete uuendamisreeglid peavad välistama vigade ja ebakõlade teket eristatavate ja kooskõlas olevate andmete haldamisel
- eraldatus (Isolation) - üheaegset juurdepääsu (concurrency) andmetele erinevate protsesside poolt peab reguleerima, et vältida konflikte ja ABHS väärastumise/rippuma jäämise (deadlock) situatsioonide vältimiseks
- kestvus (Durability) - andmete juhusikke kaotusi peab vältima või viima minimaalseks, lisades viimase kehtiva seisundi, milline süsteemil oli enne talitlushäiret, taastamisvõimaluse.
ABHS programm ei sisalda otseseid viiteid andmebaasis olevatele andmetele, kuna on võimatu eelnevalt defineerida, millised andmed tegelikult andmebaasi sisestatakse. See probleem on lahendatud selleks otstarbeks spetsiaalselt lisatud mäluruumiga, kuhu salvestatakse "andmesõnaraamat" (data dictionary), mis kirjeldab tegelikku informatsiooni, mida saab andmebaasi sisestada.
Andmete ja info salvestamine süstemaatiliselt arvuti mälus omab rea eeliseid, kuid toob kaasa ka riske, milliseid peab uurima ja lahendama. Need probleemid on andmete liiasus, terviklus, paindlikkus, turvalisus, millistest tuleb juttu lähemalt allpool.
Andmete liiasus ja vasturääkivus
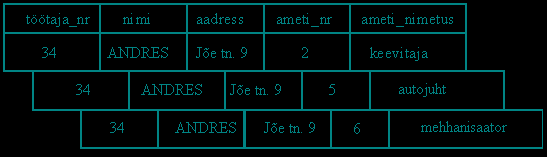
Andmete kogumisel esineb tihti olukordi, mis tulenevad reaalsest elust, näiteks andmete salvestamisel võib esineda olukordi, kus teatud andmeid on andmebaasis korduvalt, näiteks olukord, kui ühel isikul on mitu töökohta või mitu ametit, vt Sele 2. või näiteks kogutakse andmed isiku sünnikuupäeva ja vanuse kohta. Viimase näite puhul on vanuse hoidmine andmebaasis ilmselt ülearune, kuna vanust on võimalik tuletada praeguse hetke kuupäeva ja sünnikuupäeva vahena. On ütlematagi selge, et sellised andmed tarbivad rohkem arvutimälu, kui see tingimata vajalik oleks ja seetõttu aeglustavad lõppkokkuvõttes ABHS tööd.
Olukorda, kus andmebaasi tabelis on samu andmeid korduvalt nimetatakse andmeliiasuseks.
Tihti esineb ka olukordi, kus andmekogumise protsessis saadud andmed on vasturääkivad kas andmetega tegeleva isiku vea tõttu, andmeedastusprotsessi vigade tõttu või koguni pahatahtliku isiku või programmi sekkumise tõttu infotöötlusprotsessi mingil etapil.
Käideldavus, terviklus, konfidentsiaalsus
Andmete käideldavus (availability) on teabe õigeaegne ning mugav kättesaadavus ning kasutatavus selleks volitatud isikutele ning subjektidele.
Käideldavus on reeglina andmete kõige olulisem omadus - halvim mis andmetega võib juhtuda, on see, et nad pole (volitatud isikutele) kättesaadavad.
Näiteid käideldavuse probleemidest:
- Üliõpilasele antakse topelt diplom (rahvastikuregister pole kasutatav)
- Abielluvad2 abielus olevat isikut (Õnnepalee volitatud töötaja ei pääse ligi rahvastikuregistrile)
Andmete terviklus (integrity) on andmete pärinemine autentsest allikast ning veendumine, et need pole hiljem muutunud ja/või neid pole hiljem volitamatult muudetud.
Andmed on reeglina seotud selle loojaga, loomisajaga, kontekstiga jms., nende seoste rikkumine võib põhjustada ettenägematud tagajärjed.
Kompleksset mõistet, mis hõlmab andmete kehtivust, andmete kasutatavust, andmete õigsust ja andmete terviklust nimetakse andmete kooskõlalisuseks.
Tervikluse rikkumise näited:
- Riigi Teataja andmebaasi tunginud häkker saab seadusi omatahtsi muuta
- Karistusregistri eksliku muutmisega saavad vangid varem vabaks.
Tervikluseprobleemid võivad tekkida ka arvuti füüsiliste häirete korral - kas pole mingil põhjusel andmed loetavad või nad saavad rikutud mälu defektide tõttu. Kui näiteks on vaja salvestada arve andmed, siis need sisaldavad 3 informatsioonikillukest makse summa, käibemaks ja makse kuupäev. Kui üks nendest osadest on puudu või moondunud, võib see põhjustada hulga segadusi. Viimatitoodud probleemi saab lahendada tehingu tehnikaga: kui näiteks mingi osa vajalikust 3 infotükist on puudu, siis tehing tühistatakse.
Teine terviklusprobleem tekkib infotükikeste funktsionaalse sõltuvuse korral nende vahel. Olgu näiteks arve, mille sisuks on mingid kaubad ja mille päises on kliendi info (tema aadress, arveldusarve number jms.). Need kliendi andmed on erineva olulisusega, kui arve sisu, sest tavaliselt on arve sisu olulisema tähtsusega ja kliendi andmed asuvad olemasolevas teises tabelis. Sündmus, mis tühistab päise lugemise võib tekitada andmerea kliendiandmeteta (orphaned). Selliste olukordade vältimiseks kasutatakse vahendit, mis tagab andmete "viitelise tervikluse" (referential integrity). [5]
Andmete konfidentsiaalsus (confidentiality) ehk salastus on andmete kättesaadavus ainult selleks volitatud isikutele (ning kättesaamatus kõikidele ülejäänutele).
Konfidentsiaalsuse rikkumise näiteid:
- Tartu Ülikooli Kliinikumi patsientide andmed sattusid veebi
- Kaitseministeeriumi ametnik kaotas mälupulga, mistõttu sattusid salajased andmed eraisiku kätte.
Andmete paindlikkus, üheaegne juurdepääs ja turvalisus
Andmebaas võib olla suurepärane lahendus andmete paindlikuks muutmisele. On teada, et organisatsioonide andmevajadused arenevad aja möödudes ja see peegeldub hallatava info tüübis. Kui rakendusprogramm vastutab andmete juurdepääsu loogika eest, siis sisestatud uus info mõjutab otseselt vastutvat programmi ja kõiki teisi programme, mis haldavad kaasnevat (korreleeruvat) infot. Näiteks uue andmegrupi "kliendi elektronposti aadress" haldamine ei mõjuta ainult kliendiandmete haldusprogrammi vaid ka kõiki teisi programme, millistel on juurdepääs kliendiandmetele. Sellise olukorra parim lahendus on relatsiooniline andmebaas, milline annab infohalduses kõige suurema paindlikkuse.
Suurte ettevõtete korral tekib andmetele üheaegse juurdepääsu probleem. Väikestes ettevõtetes on reeglina isik või osakond, kes vastutab kliendiandmete uuendamise eest, suurtel ettevõtetel on neid reeglina mitu. Näiteks võib tekkida olukord, kus arveldusosakond (raamatupidamine) tahab muuta kliendi arveandmeid (arveldusarve) ja turundusosakond tahab muuta kliendi aadressi. Kuna andmed paiknevad samas kirjes, siis tuleb vältida kattumise probleemi. See probleem on lahendatud semaforide(semaphore) või juurdepääsu reguleeriva tehnikaga, mis võimaldab andmete muutmist ühel ABHS kasutajal samal ajahetkel, teine lihtsalt peab senikaua ootama, kuni esimene on oma muudatused teinud.
Tõsisem olukord tekib, kui kaks kasutajat tahavad uuendada kaht informatsioonitükki vastupidises järjekorras. Esimeses faasis saavad mõlemad juurdepääsu sellele infole, et seejärel määramatult oodata teise järgi, kes on blokeeritud (seda patiseisu nimetatakse ummikseisuks (deadlock)). Uued ABHS suudavad lahendada sellise olukorra jälgides blokeeritud operatsioone. Selliste olukordade parim lahendus on delegeerida kogu andmete uuendusprotsesside haldus andmebaasile.
Samuti suudab juurdepääsu turvalisusust efektiivselt hallata ABHS, kes tegutseb läbitungimatu filtrina, kuna andmetele juurdepääs toimub ainult läbi ABHS. See tähendab, et kasutaja informatsioon ja õigused salvestatakse samuti (tavaliselt krüpteeritud kujul) andmebaasi. [5]
